 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRGB-Event Fusion with Self-Attention for Collision Prediction
May 07, 2025Ensuring robust and real-time obstacle avoidance is critical for the safe operation of autonomous robots in dynamic, real-world environments. This paper proposes a neural network framework for predicting the time and collision position of an unmanned aerial vehicle with a dynamic object, using RGB and event-based vision sensors. The proposed architecture consists of two separate encoder branches, one for each modality, followed by fusion by self-attention to improve prediction accuracy. To facilitate benchmarking, we leverage the ABCD [8] dataset collected that enables detailed comparisons of single-modality and fusion-based approaches. At the same prediction throughput of 50Hz, the experimental results show that the fusion-based model offers an improvement in prediction accuracy over single-modality approaches of 1% on average and 10% for distances beyond 0.5m, but comes at the cost of +71% in memory and + 105% in FLOPs. Notably, the event-based model outperforms the RGB model by 4% for position and 26% for time error at a similar computational cost, making it a competitive alternative. Additionally, we evaluate quantized versions of the event-based models, applying 1- to 8-bit quantization to assess the trade-offs between predictive performance and computational efficiency. These findings highlight the trade-offs of multi-modal perception using RGB and event-based cameras in robotic applications.
Towards Low-Latency Event-based Obstacle Avoidance on a FPGA-Drone
Apr 14, 2025This work quantitatively evaluates the performance of event-based vision systems (EVS) against conventional RGB-based models for action prediction in collision avoidance on an FPGA accelerator. Our experiments demonstrate that the EVS model achieves a significantly higher effective frame rate (1 kHz) and lower temporal (-20 ms) and spatial prediction errors (-20 mm) compared to the RGB-based model, particularly when tested on out-of-distribution data. The EVS model also exhibits superior robustness in selecting optimal evasion maneuvers. In particular, in distinguishing between movement and stationary states, it achieves a 59 percentage point advantage in precision (78% vs. 19%) and a substantially higher F1 score (0.73 vs. 0.06), highlighting the susceptibility of the RGB model to overfitting. Further analysis in different combinations of spatial classes confirms the consistent performance of the EVS model in both test data sets. Finally, we evaluated the system end-to-end and achieved a latency of approximately 2.14 ms, with event aggregation (1 ms) and inference on the processing unit (0.94 ms) accounting for the largest components. These results underscore the advantages of event-based vision for real-time collision avoidance and demonstrate its potential for deployment in resource-constrained environments.
Towards efficient keyword spotting using spike-based time difference encoders
Mar 19, 2025Keyword spotting in edge devices is becoming increasingly important as voice-activated assistants are widely used. However, its deployment is often limited by the extreme low-power constraints of the target embedded systems. Here, we explore the Temporal Difference Encoder (TDE) performance in keyword spotting. This recent neuron model encodes the time difference in instantaneous frequency and spike count to perform efficient keyword spotting with neuromorphic processors. We use the TIdigits dataset of spoken digits with a formant decomposition and rate-based encoding into spikes. We compare three Spiking Neural Networks (SNNs) architectures to learn and classify spatio-temporal signals. The proposed SNN architectures are made of three layers with variation in its hidden layer composed of either (1) feedforward TDE, (2) feedforward Current-Based Leaky Integrate-and-Fire (CuBa-LIF), or (3) recurrent CuBa-LIF neurons. We first show that the spike trains of the frequency-converted spoken digits have a large amount of information in the temporal domain, reinforcing the importance of better exploiting temporal encoding for such a task. We then train the three SNNs with the same number of synaptic weights to quantify and compare their performance based on the accuracy and synaptic operations. The resulting accuracy of the feedforward TDE network (89%) is higher than the feedforward CuBa-LIF network (71%) and close to the recurrent CuBa-LIF network (91%). However, the feedforward TDE-based network performs 92% fewer synaptic operations than the recurrent CuBa-LIF network with the same amount of synapses. In addition, the results of the TDE network are highly interpretable and correlated with the frequency and timescale features of the spoken keywords in the dataset. Our findings suggest that the TDE is a promising neuron model for scalable event-driven processing of spatio-temporal patterns.
TDE-3: An improved prior for optical flow computation in spiking neural networks
Feb 18, 2024Motion detection is a primary task required for robotic systems to perceive and navigate in their environment. Proposed in the literature bioinspired neuromorphic Time-Difference Encoder (TDE-2) combines event-based sensors and processors with spiking neural networks to provide real-time and energy-efficient motion detection through extracting temporal correlations between two points in space. However, on the algorithmic level, this design leads to loss of direction-selectivity of individual TDEs in textured environments. Here we propose an augmented 3-point TDE (TDE-3) with additional inhibitory input that makes TDE-3 direction-selectivity robust in textured environments. We developed a procedure to train the new TDE-3 using backpropagation through time and surrogate gradients to linearly map input velocities into an output spike count or an Inter-Spike Interval (ISI). Our work is the first instance of training a spiking neuron to have a specific ISI. Using synthetic data we compared training and inference with spike count and ISI with respect to changes in stimuli dynamic range, spatial frequency, and level of noise. ISI turns out to be more robust towards variation in spatial frequency, whereas the spike count is a more reliable training signal in the presence of noise. We performed the first in-depth quantitative investigation of optical flow coding with TDE and compared TDE-2 vs TDE-3 in terms of energy-efficiency and coding precision. Results show that on the network level both detectors show similar precision (20 degree angular error, 88% correlation with ground truth). Yet, due to the more robust direction-selectivity of individual TDEs, TDE-3 based network spike less and hence is more energy-efficient. Reported precision is on par with model-based methods but the spike-based processing of the TDEs provides allows more energy-efficient inference with neuromorphic hardware.
Low-power event-based face detection with asynchronous neuromorphic hardware
Dec 21, 2023The rise of mobility, IoT and wearables has shifted processing to the edge of the sensors, driven by the need to reduce latency, communication costs and overall energy consumption. While deep learning models have achieved remarkable results in various domains, their deployment at the edge for real-time applications remains computationally expensive. Neuromorphic computing emerges as a promising paradigm shift, characterized by co-localized memory and computing as well as event-driven asynchronous sensing and processing. In this work, we demonstrate the possibility of solving the ubiquitous computer vision task of object detection at the edge with low-power requirements, using the event-based N-Caltech101 dataset. We present the first instance of an on-chip spiking neural network for event-based face detection deployed on the SynSense Speck neuromorphic chip, which comprises both an event-based sensor and a spike-based asynchronous processor implementing Integrate-and-Fire neurons. We show how to reduce precision discrepancies between off-chip clock-driven simulation used for training and on-chip event-driven inference. This involves using a multi-spike version of the Integrate-and-Fire neuron on simulation, where spikes carry values that are proportional to the extent the membrane potential exceeds the firing threshold. We propose a robust strategy to train spiking neural networks with back-propagation through time using multi-spike activation and firing rate regularization and demonstrate how to decode output spikes into bounding boxes. We show that the power consumption of the chip is directly proportional to the number of synaptic operations in the spiking neural network, and we explore the trade-off between power consumption and detection precision with different firing rate regularization, achieving an on-chip face detection mAP[0.5] of ~0.6 while consuming only ~20 mW.
NeuroBench: Advancing Neuromorphic Computing through Collaborative, Fair and Representative Benchmarking
Apr 15, 2023



The field of neuromorphic computing holds great promise in terms of advancing computing efficiency and capabilities by following brain-inspired principles. However, the rich diversity of techniques employed in neuromorphic research has resulted in a lack of clear standards for benchmarking, hindering effective evaluation of the advantages and strengths of neuromorphic methods compared to traditional deep-learning-based methods. This paper presents a collaborative effort, bringing together members from academia and the industry, to define benchmarks for neuromorphic computing: NeuroBench. The goals of NeuroBench are to be a collaborative, fair, and representative benchmark suite developed by the community, for the community. In this paper, we discuss the challenges associated with benchmarking neuromorphic solutions, and outline the key features of NeuroBench. We believe that NeuroBench will be a significant step towards defining standards that can unify the goals of neuromorphic computing and drive its technological progress. Please visit neurobench.ai for the latest updates on the benchmark tasks and metrics.
ETLP: Event-based Three-factor Local Plasticity for online learning with neuromorphic hardware
Jan 24, 2023Neuromorphic perception with event-based sensors, asynchronous hardware and spiking neurons is showing promising results for real-time and energy-efficient inference in embedded systems. The next promise of brain-inspired computing is to enable adaptation to changes at the edge with online learning. However, the parallel and distributed architectures of neuromorphic hardware based on co-localized compute and memory imposes locality constraints to the on-chip learning rules. We propose in this work the Event-based Three-factor Local Plasticity (ETLP) rule that uses (1) the pre-synaptic spike trace, (2) the post-synaptic membrane voltage and (3) a third factor in the form of projected labels with no error calculation, that also serve as update triggers. We apply ETLP with feedforward and recurrent spiking neural networks on visual and auditory event-based pattern recognition, and compare it to Back-Propagation Through Time (BPTT) and eProp. We show a competitive performance in accuracy with a clear advantage in the computational complexity for ETLP. We also show that when using local plasticity, threshold adaptation in spiking neurons and a recurrent topology are necessary to learn spatio-temporal patterns with a rich temporal structure. Finally, we provide a proof of concept hardware implementation of ETLP on FPGA to highlight the simplicity of its computational primitives and how they can be mapped into neuromorphic hardware for online learning with low-energy consumption and real-time interaction.
A Comparison of Temporal Encoders for Neuromorphic Keyword Spotting with Few Neurons
Jan 24, 2023



With the expansion of AI-powered virtual assistants, there is a need for low-power keyword spotting systems providing a "wake-up" mechanism for subsequent computationally expensive speech recognition. One promising approach is the use of neuromorphic sensors and spiking neural networks (SNNs) implemented in neuromorphic processors for sparse event-driven sensing. However, this requires resource-efficient SNN mechanisms for temporal encoding, which need to consider that these systems process information in a streaming manner, with physical time being an intrinsic property of their operation. In this work, two candidate neurocomputational elements for temporal encoding and feature extraction in SNNs described in recent literature - the spiking time-difference encoder (TDE) and disynaptic excitatory-inhibitory (E-I) elements - are comparatively investigated in a keyword-spotting task on formants computed from spoken digits in the TIDIGITS dataset. While both encoders improve performance over direct classification of the formant features in the training data, enabling a complete binary classification with a logistic regression model, they show no clear improvements on the test set. Resource-efficient keyword spotting applications may benefit from the use of these encoders, but further work on methods for learning the time constants and weights is required to investigate their full potential.
Impact of spiking neurons leakages and network recurrences on event-based spatio-temporal pattern recognition
Nov 14, 2022



Spiking neural networks coupled with neuromorphic hardware and event-based sensors are getting increased interest for low-latency and low-power inference at the edge. However, multiple spiking neuron models have been proposed in the literature with different levels of biological plausibility and different computational features and complexities. Consequently, there is a need to define the right level of abstraction from biology in order to get the best performance in accurate, efficient and fast inference in neuromorphic hardware. In this context, we explore the impact of synaptic and membrane leakages in spiking neurons. We confront three neural models with different computational complexities using feedforward and recurrent topologies for event-based visual and auditory pattern recognition. Our results show that, in terms of accuracy, leakages are important when there are both temporal information in the data and explicit recurrence in the network. In addition, leakages do not necessarily increase the sparsity of spikes flowing in the network. We also investigate the impact of heterogeneity in the time constant of leakages, and the results show a slight improvement in accuracy when using data with a rich temporal structure. These results advance our understanding of the computational role of the neural leakages and network recurrences, and provide valuable insights for the design of compact and energy-efficient neuromorphic hardware for embedded systems.
Spike-based local synaptic plasticity: A survey of computational models and neuromorphic circuits
Sep 30, 2022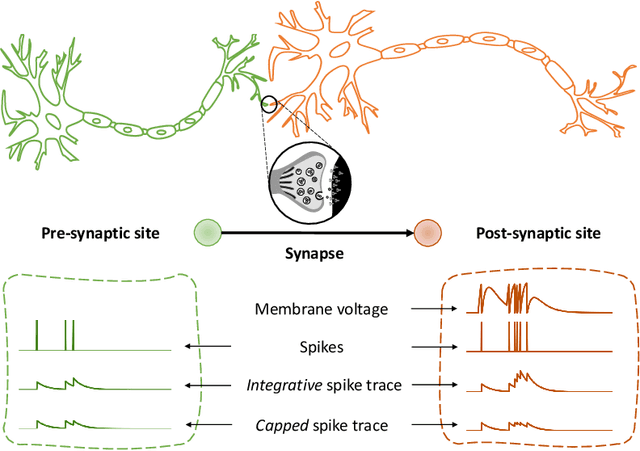
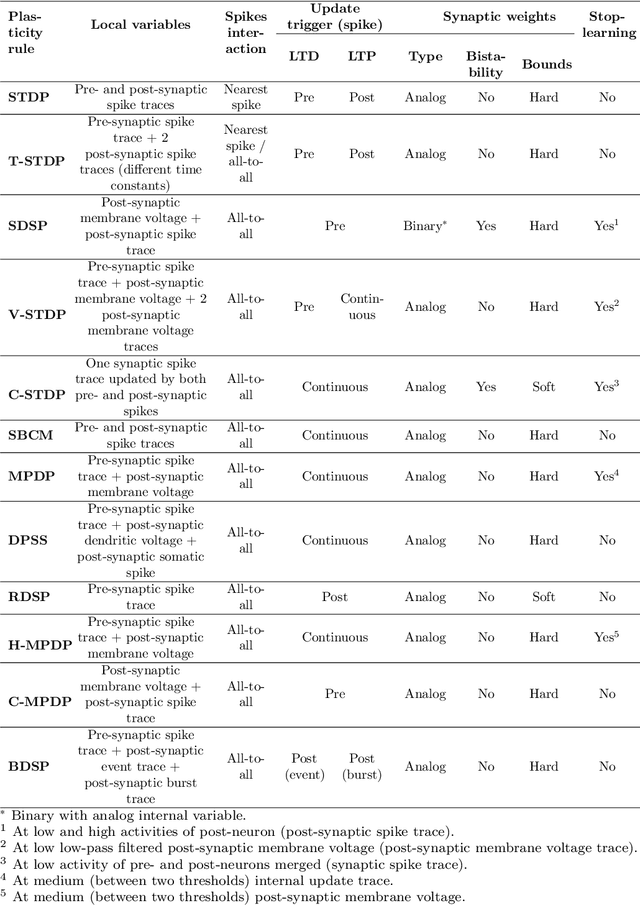
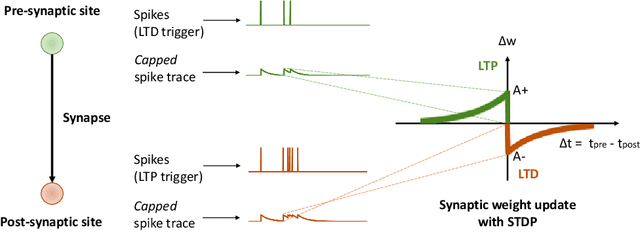

Understanding how biological neural networks carry out learning using spike-based local plasticity mechanisms can lead to the development of powerful, energy-efficient, and adaptive neuromorphic processing systems. A large number of spike-based learning models have recently been proposed following different approaches. However, it is difficult to assess if and how they could be mapped onto neuromorphic hardware, and to compare their features and ease of implementation. To this end, in this survey, we provide a comprehensive overview of representative brain-inspired synaptic plasticity models and mixed-signal \acs{CMOS} neuromorphic circuits within a unified framework. We review historical, bottom-up, and top-down approaches to modeling synaptic plasticity, and we identify computational primitives that can support low-latency and low-power hardware implementations of spike-based learning rules. We provide a common definition of a locality principle based on pre- and post-synaptic neuron information, which we propose as a fundamental requirement for physical implementations of synaptic plasticity. Based on this principle, we compare the properties of these models within the same framework, and describe the mixed-signal electronic circuits that implement their computing primitives, pointing out how these building blocks enable efficient on-chip and online learning in neuromorphic processing systems.